实例分析:emoji 符号无法显示?
在 AppSo iOS/Android app 的开发中,曾经遇到这样的情况:用户用微信授权登录 app 后,昵称中含 emoji 符号无法显示,像这样——

问题一:友盟的组件闯祸了
上述显示不正常的 emoji,其 Unicode 编码为 U+F61E,凭直觉判断应该是被截断(truncate)了。AppSo iOS app 在授权部分使用的是友盟的组件,这款组件有些年头,后端服务器用的是 Mysql,出现截断也是很合理的。一看,果然,微信那边实际存储的编码为 U+0001F61E。破案了。解决方案很简单,替换掉友盟的组件,授权流程用微信官方的 sdk。下面我们稍微花点时间,从编码层面看看截断过程是怎么发生的。
utf-8 truncate
Unicode(万国码)是抽象编码集,也就是说,它就像一本字典,记着编码——字符的对应关系,但它不负责实际的编码存储和传输。目前最流行的用于传输和存储的家伙叫 utf-8,也就是 Unicode Transformation Format 8,是一种 8 位的变长编码方法。utf-8 向下兼容 ASCII 码,可理解为 ASCII 码的超集或扩展集。当一个字符属于 ASCII 集时,utf-8 使用一个 byte,也就是 8 bit 进行编码,超出后,则使用两个 byte,再超出则使用 3 bytes,以此类推。不过 03 年 11 月受 RFC3629 约定,最长到 4 个字节。
那么它是如何做到变长的呢?我们看 RFC3629——
Char. number range | UTF-8 octet sequence
(hexadecimal) | (binary)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
好了,我们回过头来看截断( truncate) 的过程。
Unicode 有两个编码集,UCS-2 和 UCS-4。UCS-2 使用 2 个字节,UCS-4 使用 4 个字节。为什么有两个,因为容量。我们算一下数:2 bytes = 16 bits = 2^16 = 65536 个字符,也就是说 UCS-2 顶天了也就能表示 6 万多字符,而光汉字(GB18030)就已经超过 7 万字,显然是不够的。
上面说到,Unicode 是抽象编码集,实际的传输是 utf-8。我们先将 Unicode 转换成 utf-8.
Yergeau Standards Track [Page 3]
RFC 2279 UTF-8 January 1998
UCS-4 range (hex.) UTF-8 octet sequence (binary)
0000 0000-0000 007F 0xxxxxxx
0000 0080-0000 07FF 110xxxxx 10xxxxxx
0000 0800-0000 FFFF 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-001F FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0020 0000-03FF FFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0400 0000-7FFF FFFF 1111110x 10xxxxxx ... 10xxxxxx
根据 RFC 2279 ,0001F61E 在 0001 0000-001F FFFF 范围,对应的 utf-8 的范式是 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。0001F61E 的二进制是 11111011 000011110,从右往左(左边补零),将数字填入 x 的位置,即得到 utf-8 编码,如下图。
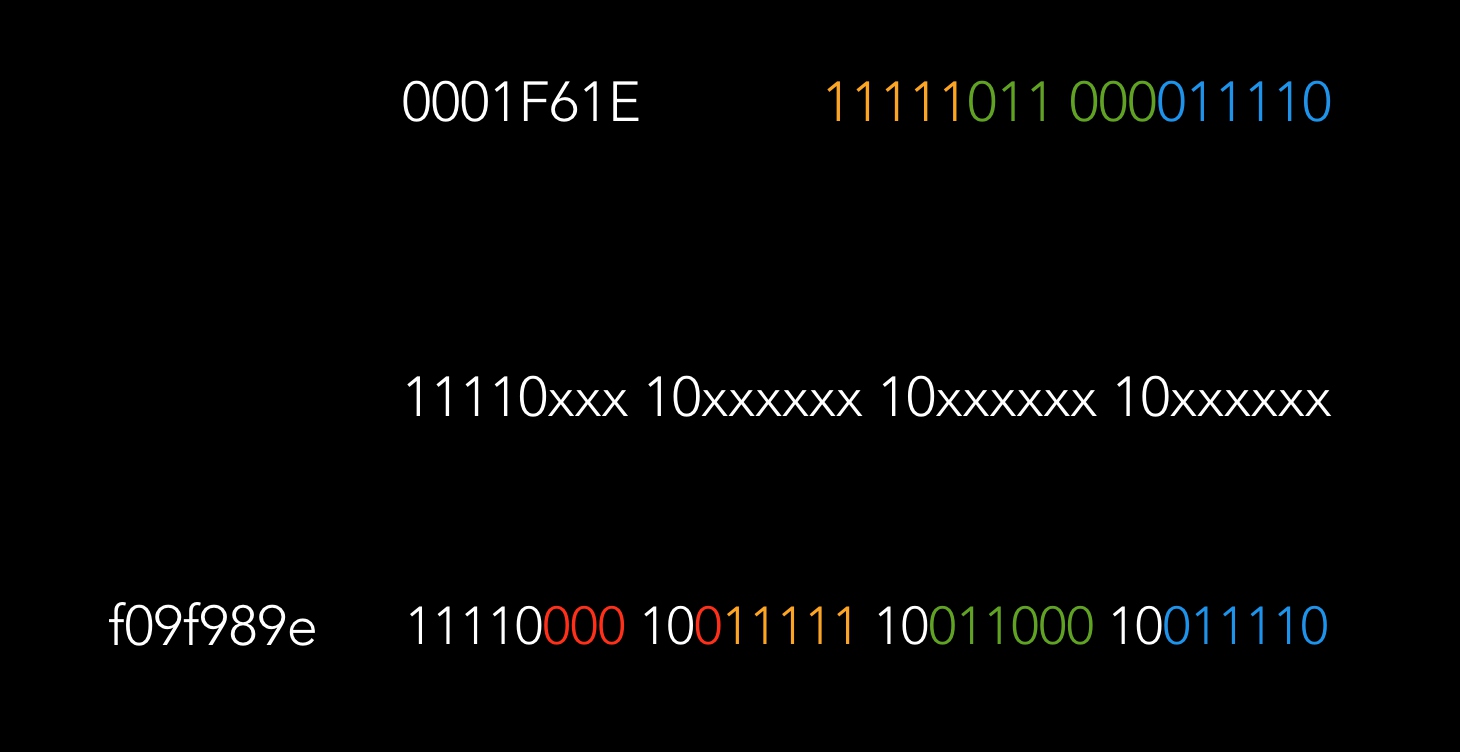
而在早期的 Mysql 中,不支持 4 bytes 的 utf-8,将截断成 3 bytes,截断过程如下图所示。

我们将截断后的 utf-8 转换成 Unicode,就得到了 U+F61E。
问题二:不再使用友盟,可 emoji 还是无法显示
直接从微信获取数据,还是存在无法显示的 emoji。比如说,这位:。
|
|
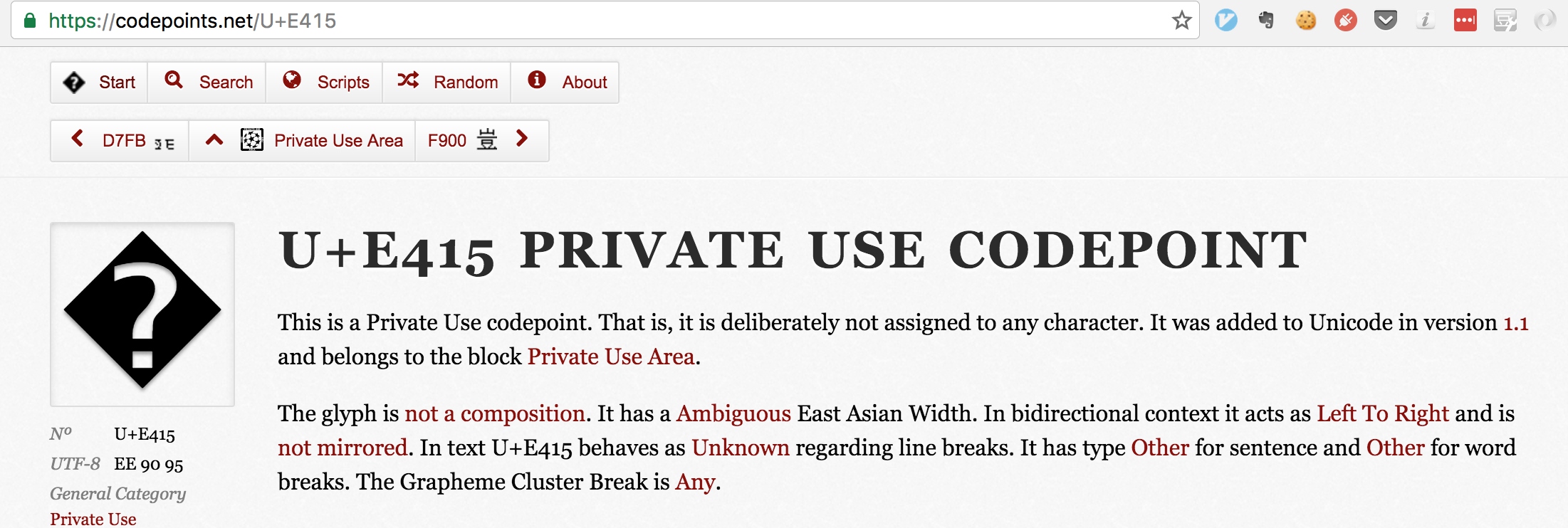
U+E415,属于 PUA(Unicode Private Usage Area),Unicode 中未分配定义的码段。现在问题来了,我们知道这个字符是一个 emoji,但拿到的编码却是一个 PUC(Private Usage Code)。看来有必要回顾一下 emoji 的历史才行。
Emoji 早期的编码方案
在 emoji 的维基百科上,有这么一段——
Emoji were first defined in Unicode 6.0, and pre-6.0 characters were only defined as emoji in 6.0 or later.
也就是说,在 Unicode 6.0 将 Emoji 正式纳入之前,Emoji 是以偷渡客的姿势存在的。
emoji 中的最流行版本 Soft-bank 版本,使用的是 Soft-bank PUA,U+E415 是其中之一。这个版本的最大用户群体是 Apple iOS 5 之前的系统用户。
在 Background data for Proposal for Encoding Emoji Symbols 页面可以找到 Soft-bank 版本和 unified 版本的对应关系。U+E415 对应的是 U+1F605,😅。
问题已经定位,现在,要做的就是,如何将偷渡版(Soft-bank PUA)emoji 正确显示出来?
为什么微信不一次性将旧码替换成新的统一码?
祸从微信起,当然要先追究微信的责任。微信为什么不?
其实同样的问题,也可以问操作系统,操作系统为什么不?
仔细想想,答案很简单。PUA 是私有码段,用途是各个组织自己内部使用来做些爱做的映射。苹果有苹果的映射关系,微软有微软的映射关系。回到 emoji,在统一之前,市面上有三大派系——Google、Soft-bank(Apple)、NTT DoCoMo。都用的是 PUA,也就是说,一个编码,在 Google 那边的 emoji 是😇(天使),在 Soft-bank 那边可能就是😈.
而在另一种极端场景下,一个用户还用着早期的 iPhone 3GS,系统里内置的还是 Soft-bank 的 emoji 编码,他喜爱 emoji,并且将其中一个座位自己的微信昵称。这时,如果微信将这个编码替换成统一码,由于统一码在该系统上没有对应的字符,用户的昵称将不能正确显示。这对于这个可怜的用户来说,自然是一个 bug。
因此,微信的解决方案是,在每一个客户端维护一份映射表,从客户端解决显示兼容问题。
我们怎么做?
从工程上考虑,客户端维护映射,成本上比统一处理要高。且其正面效果随着时间的流逝会越来越弱,因为机器在逐年更新换代。历史包袱越来越轻。考虑到 AppSo 是面向喜欢研究 app 的用户群体,这个群体的鲜明特征就是使用旧设备的极少。综上,我们从服务端解决兼容问题。
统一处理需要做的事情是不少的。除了一次性的批量替换数据库中的内容,还有新增内容的过滤,且新增内容的来源很多,这样过滤器就要支持得很好才行,维护成本过高。
而换个角度,从服务器输出内容处做过滤,则要简易得多。最终,我们采用 nginx lua script 做 response body sub filter 的解决方案。这个方案的具体细节在此不再赘述。
更新:macOS 10.12 与 iOS 10 iPhone 、iPad 上对 PUA 的支持情况
以维基百科上 Emoji 页面上 PUA 的章节为例:
- macOS 10.12 Safari

- iOS 10.0.1 iPhone 6s Plus
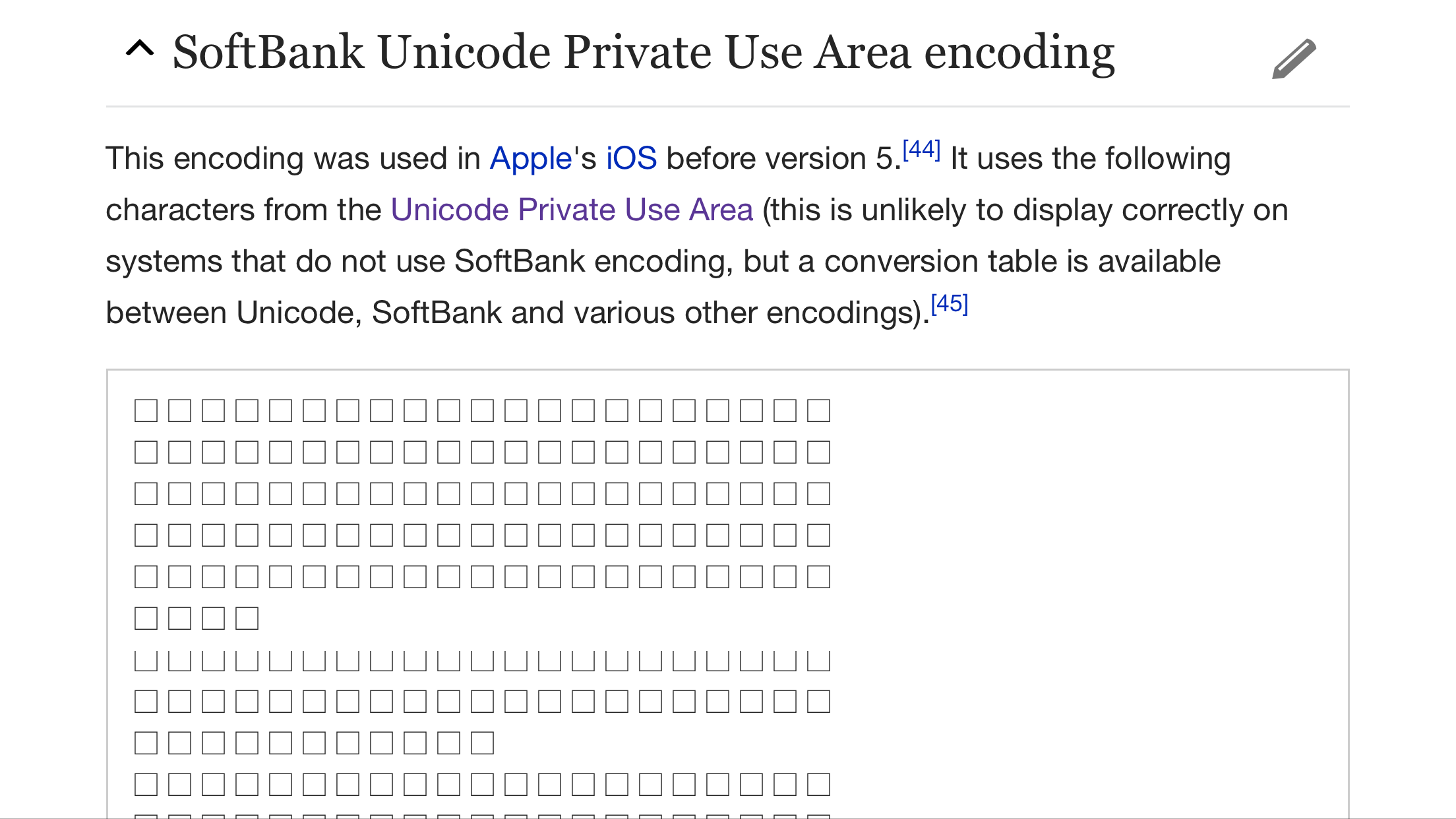
- iOS 10.0.1 iPad Pro 9.7
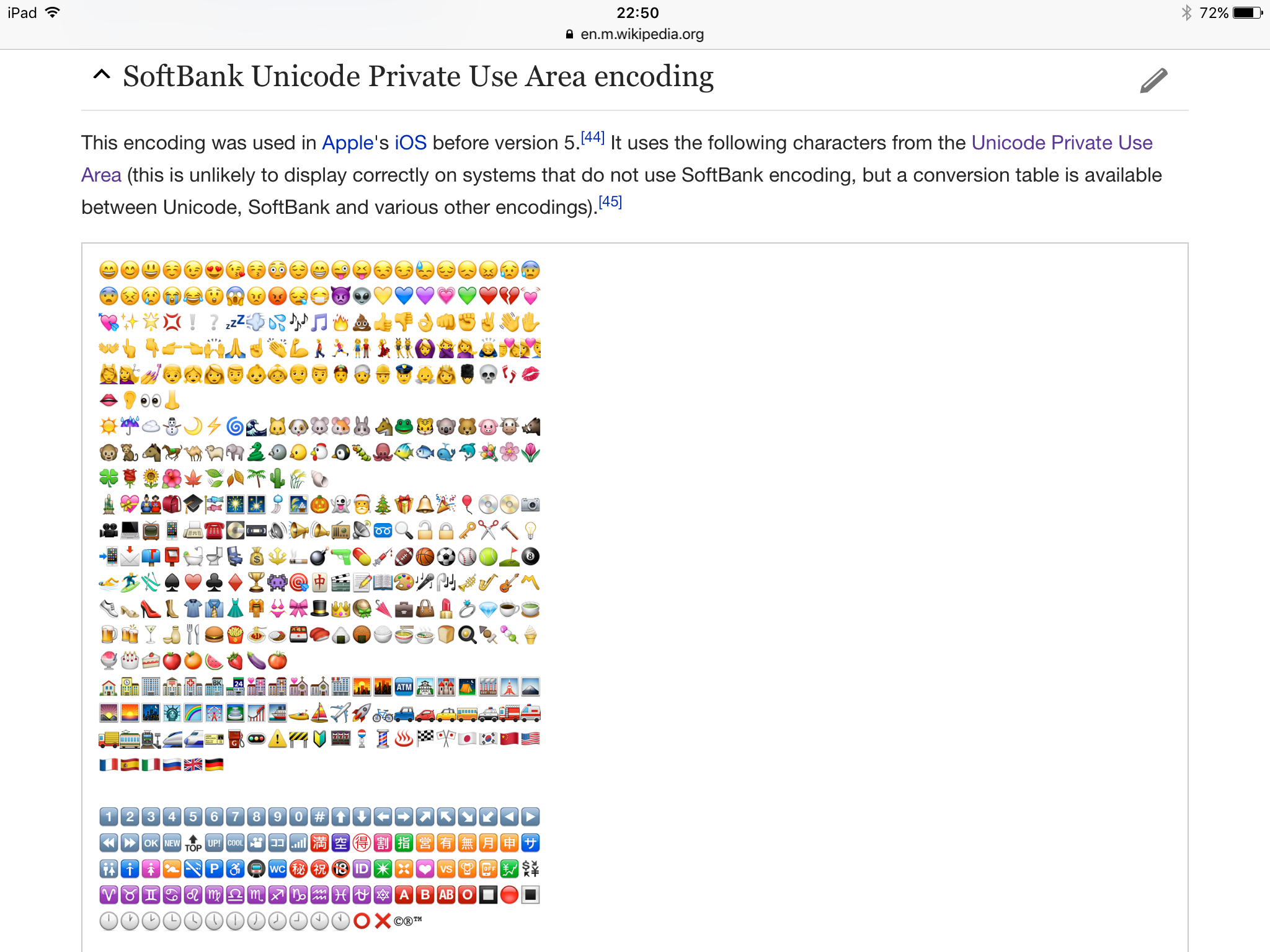
可以看到,虽然同为 iOS 10.0.1,iPad Pro 上对 Emoji PUA 是支持的。暂时不知道为什么官方是这么设定。