本文由在 10 月 26 日的 GTLC 成都站上进行的「日迭代 1000+,该拿什么来换?」的主题分享整理而成,有大量删减。原载于TGO鲲鹏会公众号《打造高速运转的迭代机器:现代研发流程体系打造》。
开场

上得台来得做一个自我介绍,名字职位刚主持人已经说了,我说点和前几位老师不一样的地方:从成分上讲,我属于 1/3 到 1/4 个四川人。我家里弟兄三人,我行三,大嫂都江堰人;二嫂乐山人;我老婆…很遗憾我没有完成任务。今天特别感谢 TGO 给我这个机会回乡省亲。
我交这个底给大家,不是为了套近乎,打感情牌,不存在。我就是想朴素地告诉大家:虽然我会耽误大家吃午饭,但是不要有打我的想法,毕竟我在这边的家族势力大家也都知道了对吧。
好了,闲话少叙,让我们在接下来的 2 个小时里好好聊聊工程效率问题。(开个玩笑,是 45 分钟,我看到不少人脸都白了)
DevOps 是最简单的问题
今天时间有限,我们主要聊聊持续交付里的重点、难点和必考点(敲黑板。下边我们先一起快速地走一遍流程,大概 50 页的样子,不要害怕。
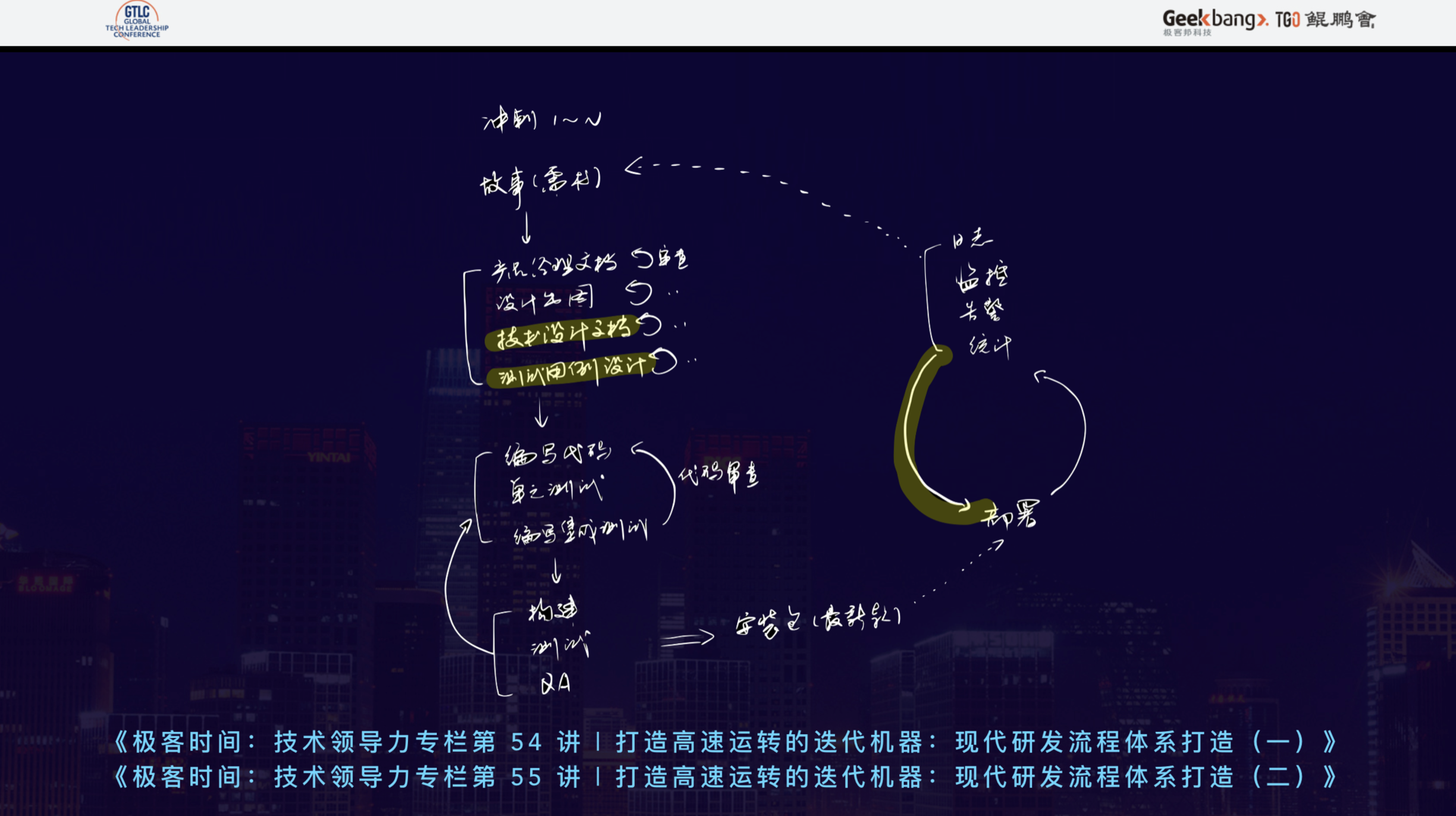
当我们聊到 DevOps 和 CI/CD 时,都会被形容成流水线。今天,我以爱范儿团队的一个产品实际流程为例,画了下图:

上图中需要注意的是,研发和生产可以完全独立的两个生命周期,接下来我将从生产说起。
AutoScale 自动扩缩容

生产环节中的所有系统都只服务于一件事——不宕机。那么如何才能实现不宕机呢?随时随地快速部署,每一次 Scale 都是一次部署。
上图中列了生产中的必要组成部分——日志系统、APM 探针服务、统计监控服务、错误上报服务、OnCall 报警服务以及 AutoScale 机制。他们的关系应该是下图:

上述这些子系统,归根结底不是给人看的,而是给 AutoScale 机制看的,人永远没有机器响应得快。我们擅长的是:发现规律,制定规则;机器擅长的是执行。因此,我们需要通过编排这些系统的数据流向,让这个生命周期自己运转起来。
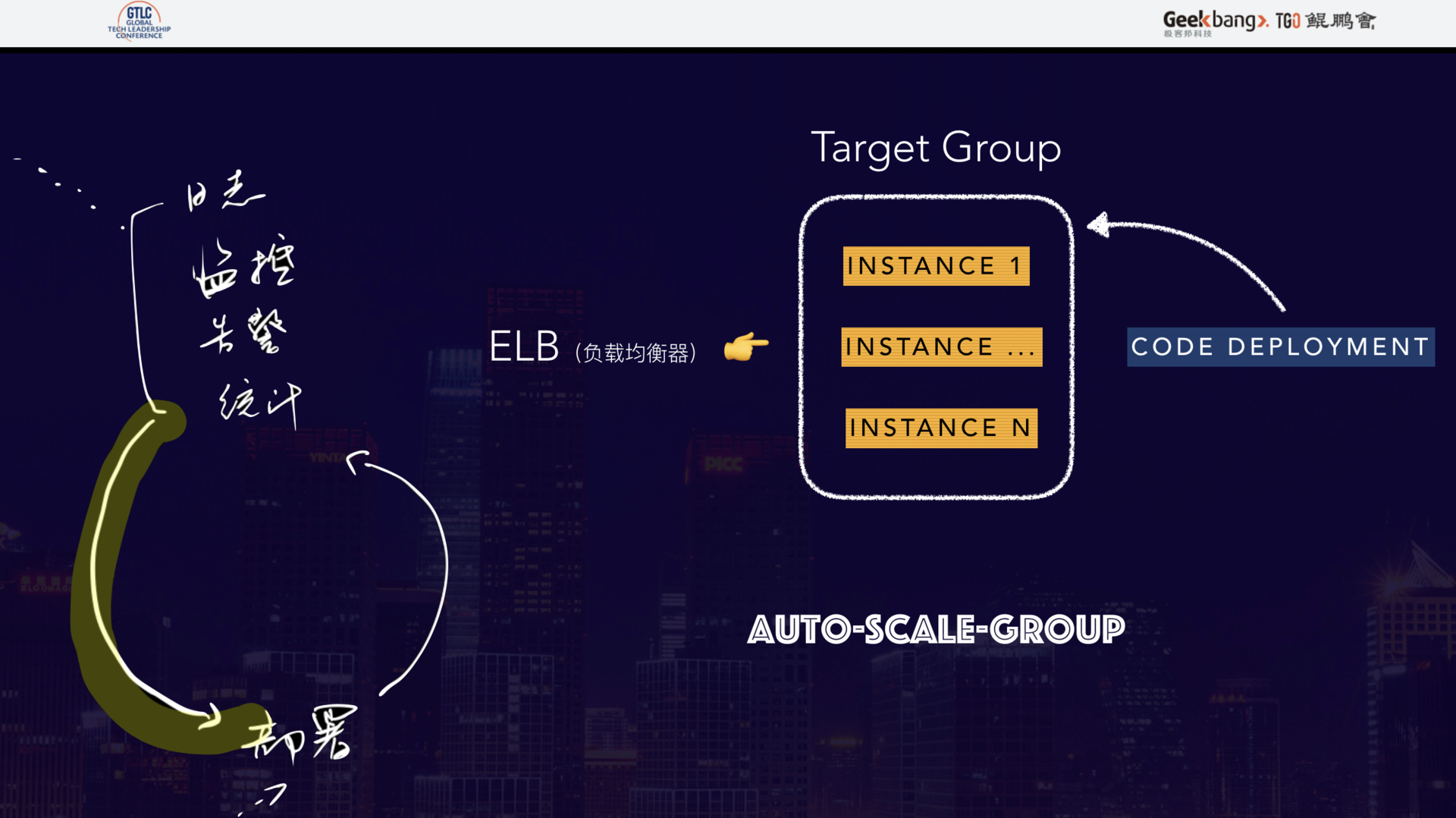
以 AWS 的 ASG 为例,一个自动扩缩容组主要包括:一个 ELB 弹性负载均衡器、一组应用服务器、一个部署机制以及一些扩缩容规则,下图就是一个典型的常用规则:ELB 的指定单位范围内的平均响应时间超过一个阈值时,增加一些机器到服务器组。

自动扩缩容机制会随时根据这些规则对数据进行测算,满足条件后则执行响应动作。
如果规则很多,互相干扰怎么办?增加 Cooling Down 机制就可以在一定程度上避免干扰,让不同的规则可以互相辅助。
APM、日志和监控

Scale 解决了,再来看看让 Scale 可以工作的各个背后的系统。
APM 探针服务是我个人认为最该投入预算的地方,原因在于它可以近乎实时的细化到每一行执行代码中,将生产中的性能情况曝露出来,这对持续的性能调优帮助非常大,比传统的测试加线上日志、监控来定位问题效率高很多倍。
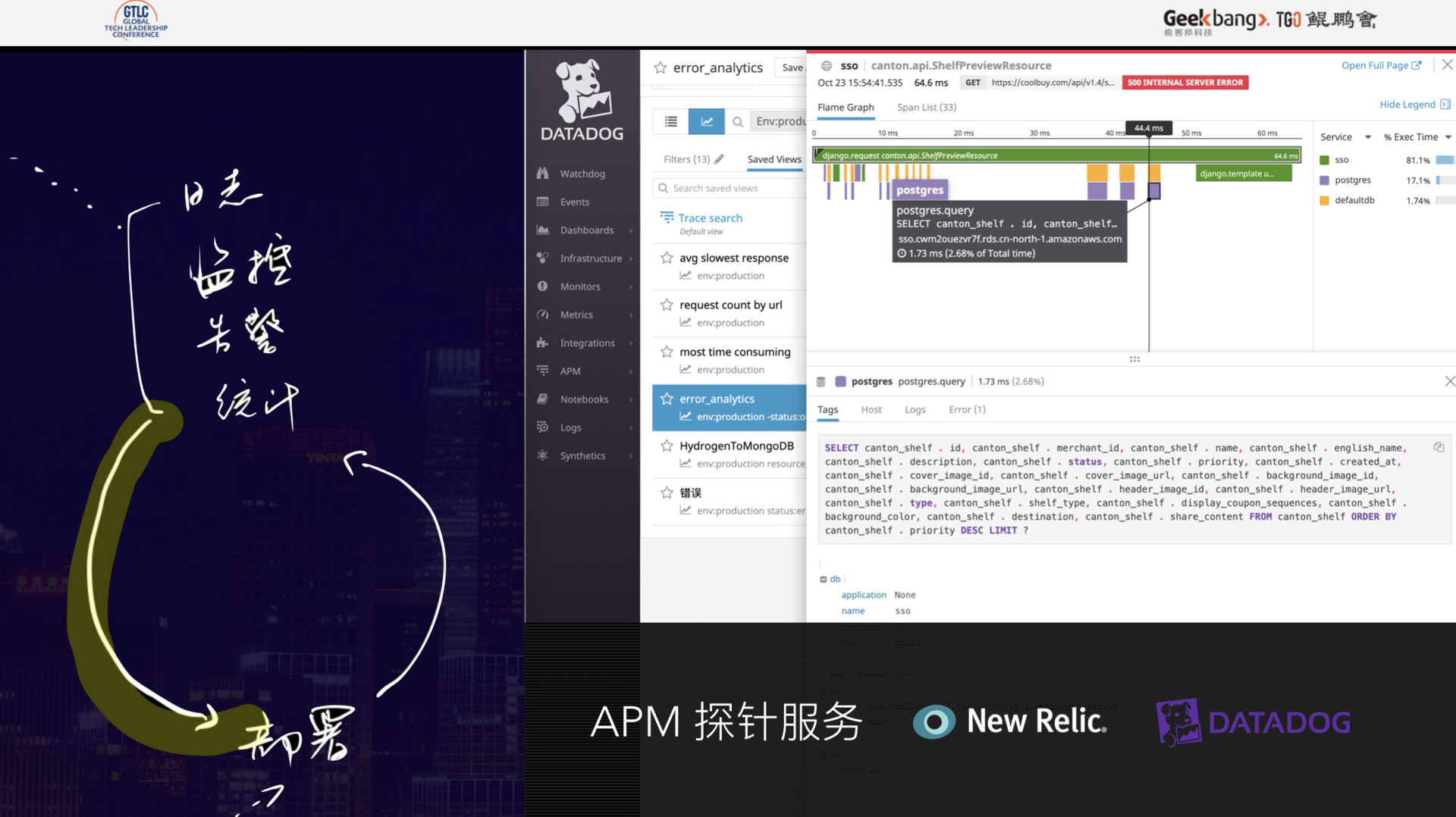
日志和统计监控,相信大家多多少少都有实践,这里我将分享爱范儿的一些实践经验。
从我们的实践经验来看,日志用 AWS 的 Cloudwatch 比较划算,再结合自己写的 Node Exporter,可以通过比较廉价的方式将几年的日志保存起来,并可以随时检索。
统计监控主要就是在用了 APM 的基础上, 再根据自己的业务情况,对感兴趣的流程环节加强统计和监控。比如电商业务,会对下单到派单关注比较多,因此需要增加更多维度的监控。一般是使用 Prometheus 和 Grafana 来做 TS 数据的上报存储,再和其他系统联动起来。
说到这儿,生产环节基本上就搞定了——给机器们按照定义好的规则,自动地进行线上的运维工作。实在处理不了的,通过 OnCall 和 Error Report 的方式让工程师加入进来。
这里具备一个基本的原则是,处理线上的事情,机器永远可以做得比人快,比人精准。所以,这套流程,尽可能的让机器更多地参与到执行上,工程师更多地参与到线上模式的观察、规则的指定和数据流的编排中。
让高迭代有高质量

说完生产,再说回研发。
上图中,左边这条研发线,归根结底是为了生产出一个可用于生产的安装包(交付物)。恕我直言,当前大多数吹嘘自己可以实现快速迭代的公司都是都是虚假繁荣的,这是为什么呢?
我们来算一笔账,团队日发布 100 次,假设 2 个小组并发工作,并不间断地工作 10 个小时,然而算下来每次发布只有 12 分钟。太多公司的主流程回归测试就没有做到自动化了,这就变成测试工程师需要在 12 分钟内完成一次回归,这几乎不可能。以典型的电商产品为例,从浏览商品到发货主流程,100 个用例就算最少了,人工 1 个小时都比较困难。
因此,想要研发的效率提速,首先需要解决自动化测试,否则都是空谈。

接下来,我将介绍下 CI 的部分。在尝试了众多 CI 之后,我们最终选用 Bamboo,主要原因有 2 个:
1、随着项目规模变大,一次迭代产生的 CI 任务会快速增加,像现在我们的 SSO 模块,一次提交,需要跑 20 个前端构建任务,这很容易导致繁忙的时间段,需要上百台机器才能完成所有构建,不然就会排队等待,影响开发效率。Bamboo 很好的整合了对 AWS 的 Spot Instance 支持,相当于引入了 AutoScale 到 CI 系统。可以很好地支撑高峰期的需求,同时又不用提高太多成本;
2、CI 是串联项目系统、代码库、生产系统的中间环节,系统的数据连通性必须要好。Bamboo 能很好地打通这些系统的数据。
说回测试,单元测试和集成测试。单元测试的好处大家都清楚,或许大家多少也都经历过。我们的一个模块,测试到 10,000 个的规模后,单台机基本上跑不动,花了点时间将测试框架改造成可支持跨机器的分布式系统,这才让单次的测试控制在 10 分钟之内。然而这些都是必然会出现的代价,但能做还是要尽量做下去。
接下来,我将重点说说集成测试。
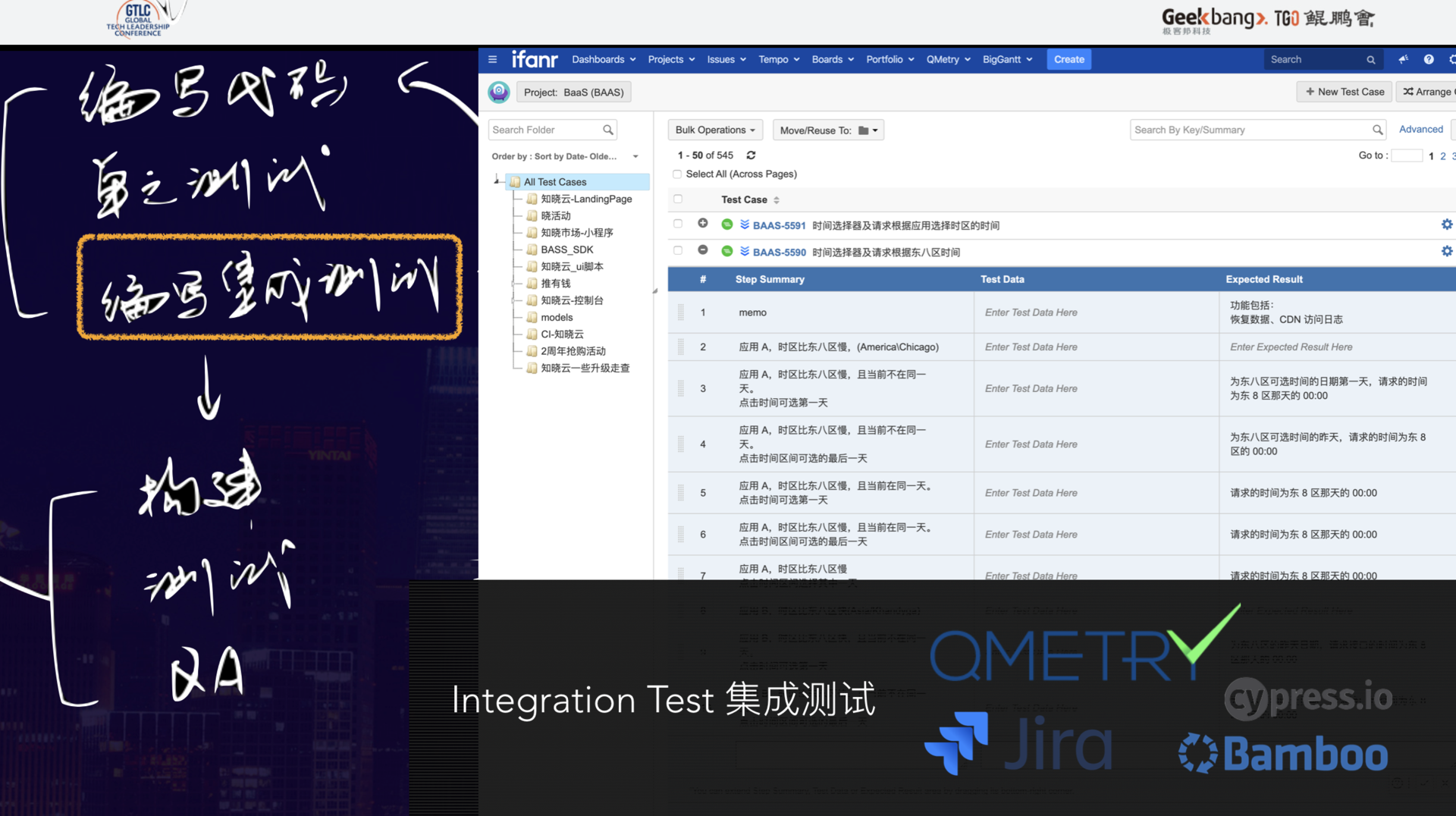
大家都知道自动化集成测试,但都不怎么愿意投入资源做自动化集成测试。
招测试工程师时,我发现基本上 90% 的工程师还在用 Excel 来管理测试用例,稍微好点的用 XMind。我认为,这是非常离谱的,原因很简单:测试用例和架构设计一样,甚至测试用例会更加复杂,因为它既是项目管理的一个环节,也是指导研发的一个环节。比如,之前所提到电商主流程中的 100 个用例,这个主流程一般怎么操作呢?就是对 100 个用例进行筛选,将主线分支的用例归到主流程组,然后对这些用例编写测试脚本,运行中的测试脚本每一轮都会将测试结果同步到用例管理系统、项目管理系统。因此,测试用例必须用工程化的管理系统。
目前,爱范儿采用 Qmetry 和 Jira 来进行整个系统的搭建,测试脚本这块,我们从 Selenium 换到了 Cypress,因为它能更好地处理前端的 UI 集成。
测试环节上自动化,才能从本质上让高速迭代成为可能,真正地实现从写完代码到代码进入生产发生在 10 分钟内,并且还不用提心吊胆,担心随时出大事。
让代码腐化速度尽可能延缓
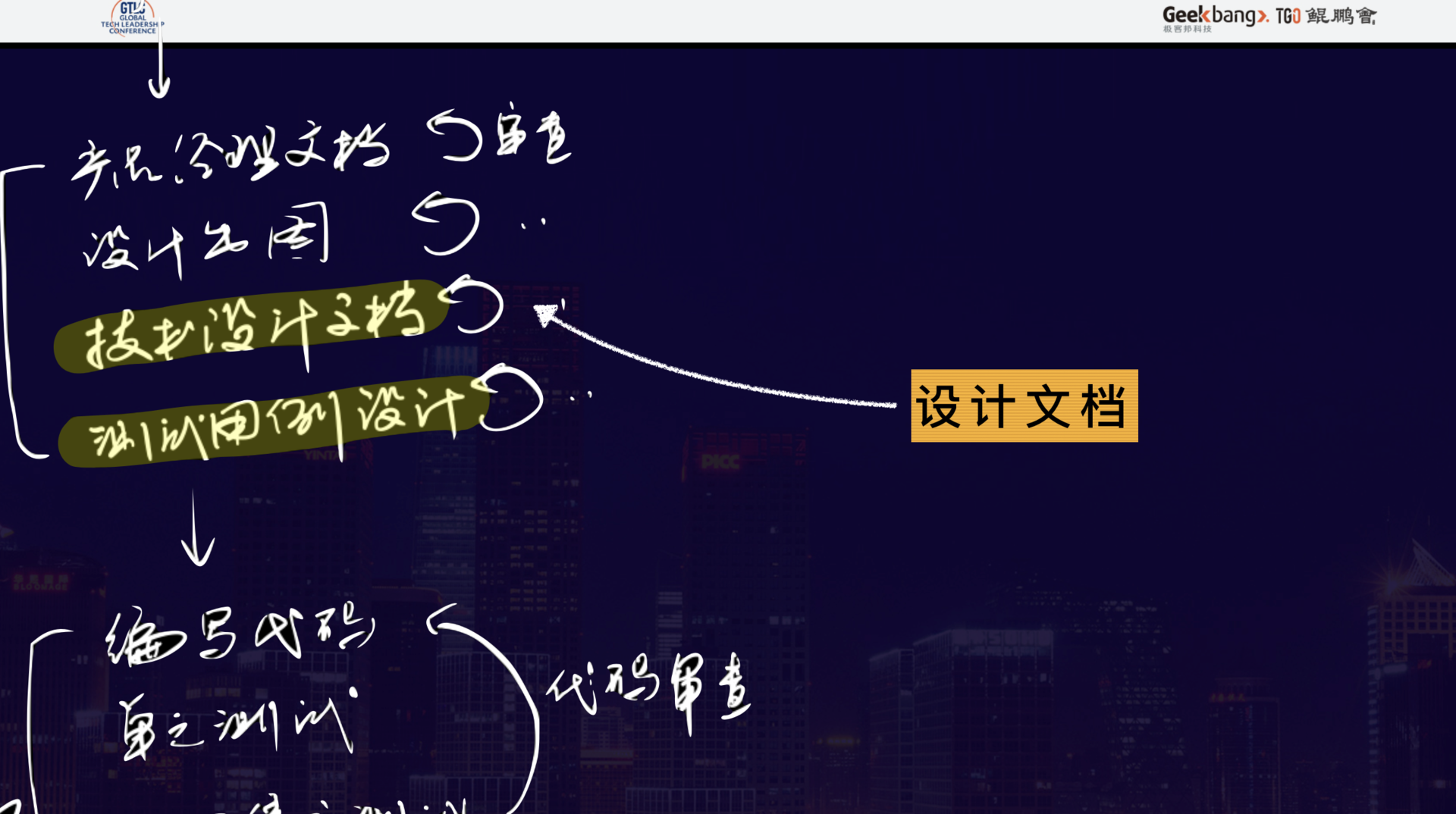
下面来重点说下我们正在推行的一个环节——设计文档。
设计文档是从工程师领取需求后,到工程师开始写代码之前,必须要完成的一件事情。和代码交付一样,该过程必须经过审批流程,这是为了解决什么问题呢?
原因得从根源说起,软件工程脱胎自建筑工程,架构师的英文 title 是 Architect,也就是建筑师。所以今天特别荣幸能和各位“包工头”欢聚一堂,但是软件工程无法使用建筑工程那套东西。以当前我们所在的会场为例,从会场立项到竣工,工程蓝图基本上就那份,从来不用改,房子建好了找个隐秘的角落把图纸封存,等下次房屋损坏再拿出来,这是不是很省事?但是软件工程办得到吗?
现在的互联网项目,就算项目立项时准备了非常详实、完备的架构设计文档,但是只要这个项目在正常迭代,过了半年后,基本上除了核心的地方之外,其他地方的代码和当初的架构设计一点关系都没有了。我相信现场肯定有同学接手过老项目对吧,你们觉得痛苦吗?今天,我们就可以知道痛苦的根源在哪里了。
设计文档,就是为了解决这个问题而存在的,可以让架构设计和需求迭代同步起来。
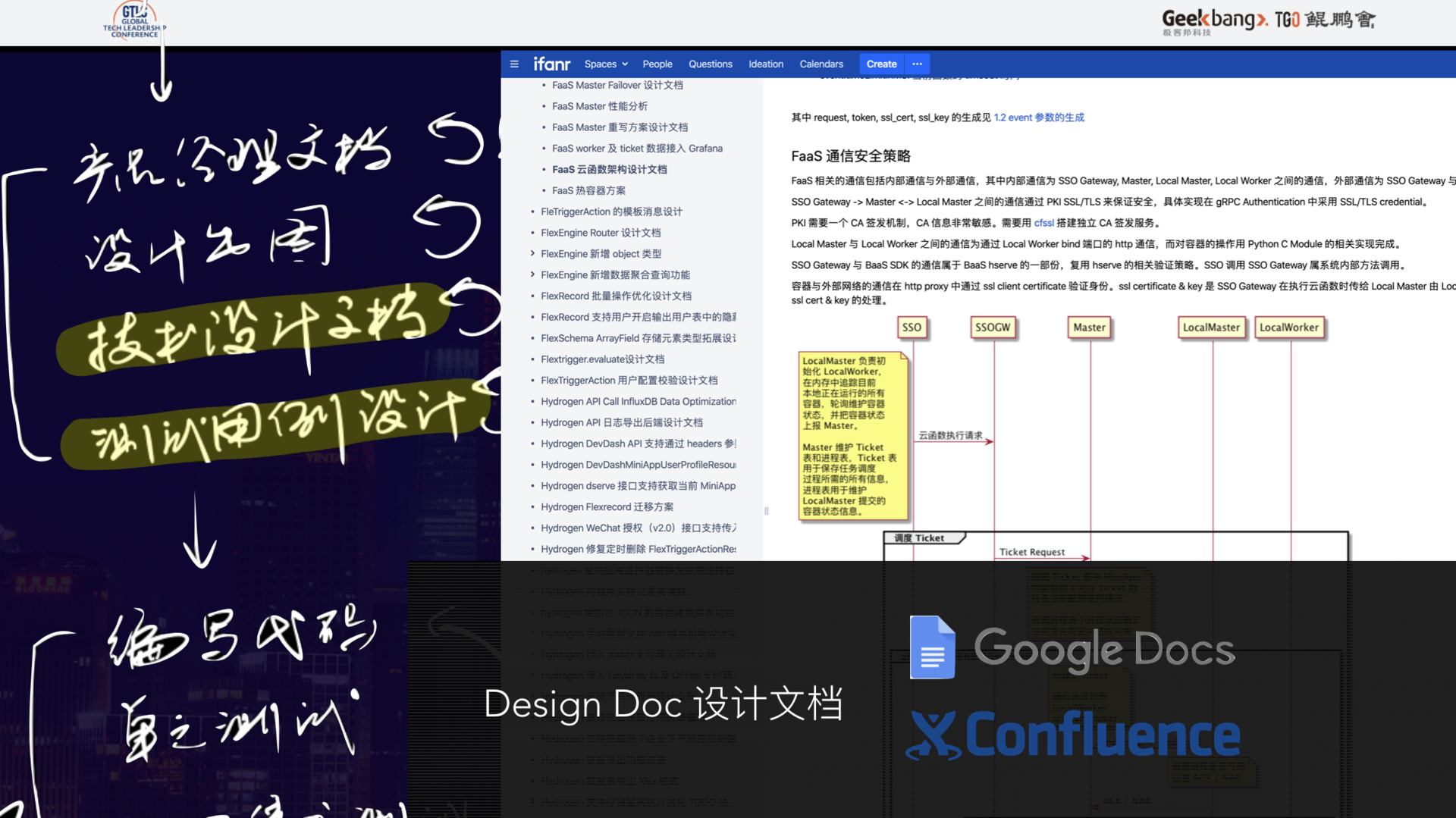
那么设计文档怎么操作呢?我认为,设计文档系统的要求只有两点:
1、实时协作,随时可以评审、讨论;
2、文档有版本管理,像代码库一样,方便随时查看心路历程。
我们一直在用 Google Docs 和 Confluence,最终归档在 Confluence。
现代组织的知识体系建设是打造可追溯的现场

设计文档可以解决代码腐化问题,但是组织依然会陷入混沌,隔段时间加入的新人还是会面临各种不知道状况的 moment。产生这个问题的根源主要在于,研发流程涉及到的岗位众多,各岗位使用的系统不一样,系统间不打通,很难对当时的现场进行回溯,从而无法弄清楚当时的情况,如果只是做 Wiki 的建设,那是远远不够的。
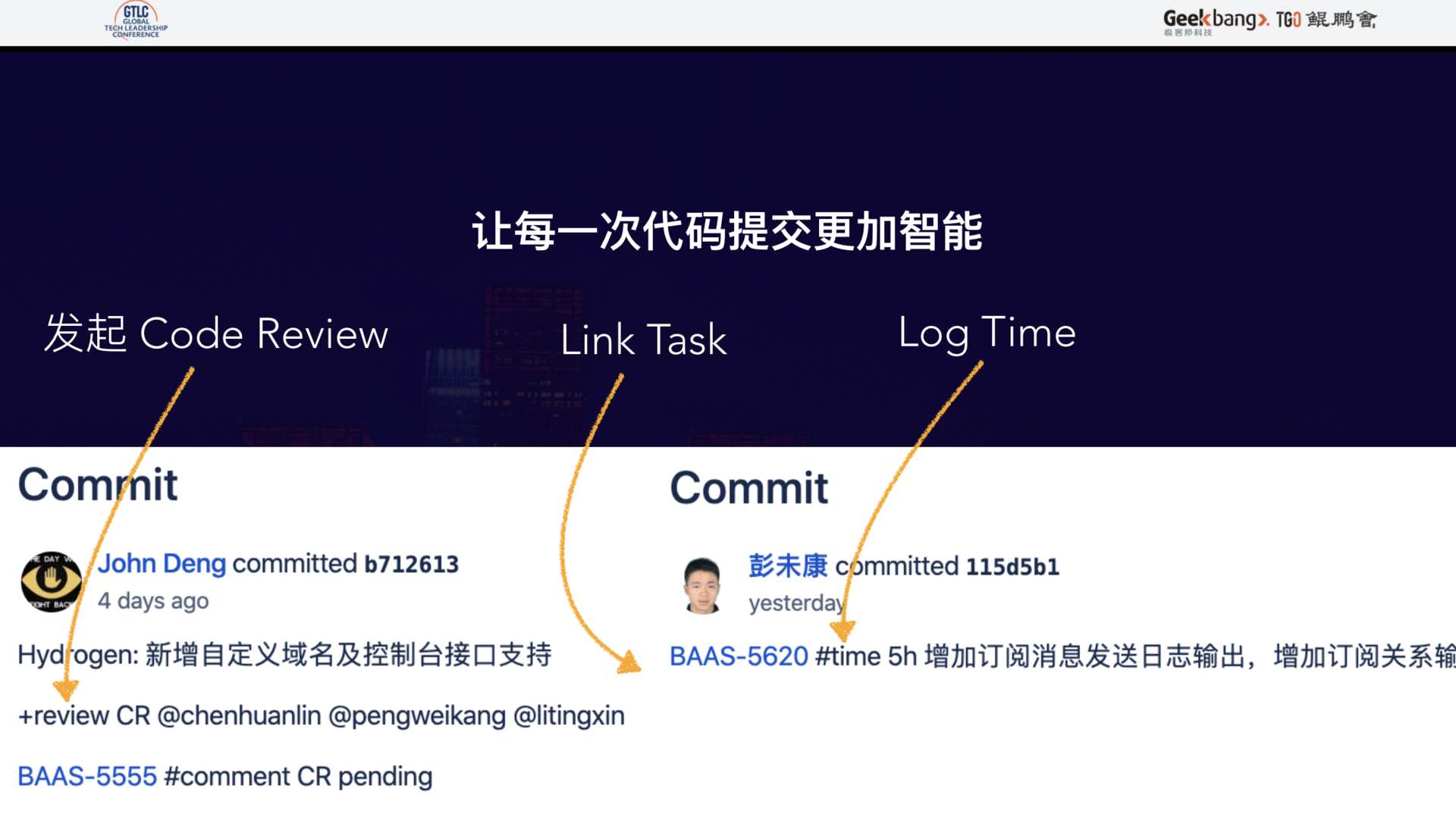
Atlanssian 公司做得最好的一件事就是通过买的方式,将研发流程中的系统串联起来。任何时候,你都可以通过一次代码提交找到对应的任务、测试结果、需求说明和线上事故。
现代组织的协作方式
最后,聊一下最重要的话题——协作。
刚才我提到了流程的建设,但归根结底,流程是服务于各个岗位的人。而我也相信,随着这几年即时通信领域的发展,基本上每个团队都有非常好的在线沟通体验。但是仍然有一个问题需要解决——流程中有那么多机器,那么人和机器的沟通都应该变得更加高效才可以。
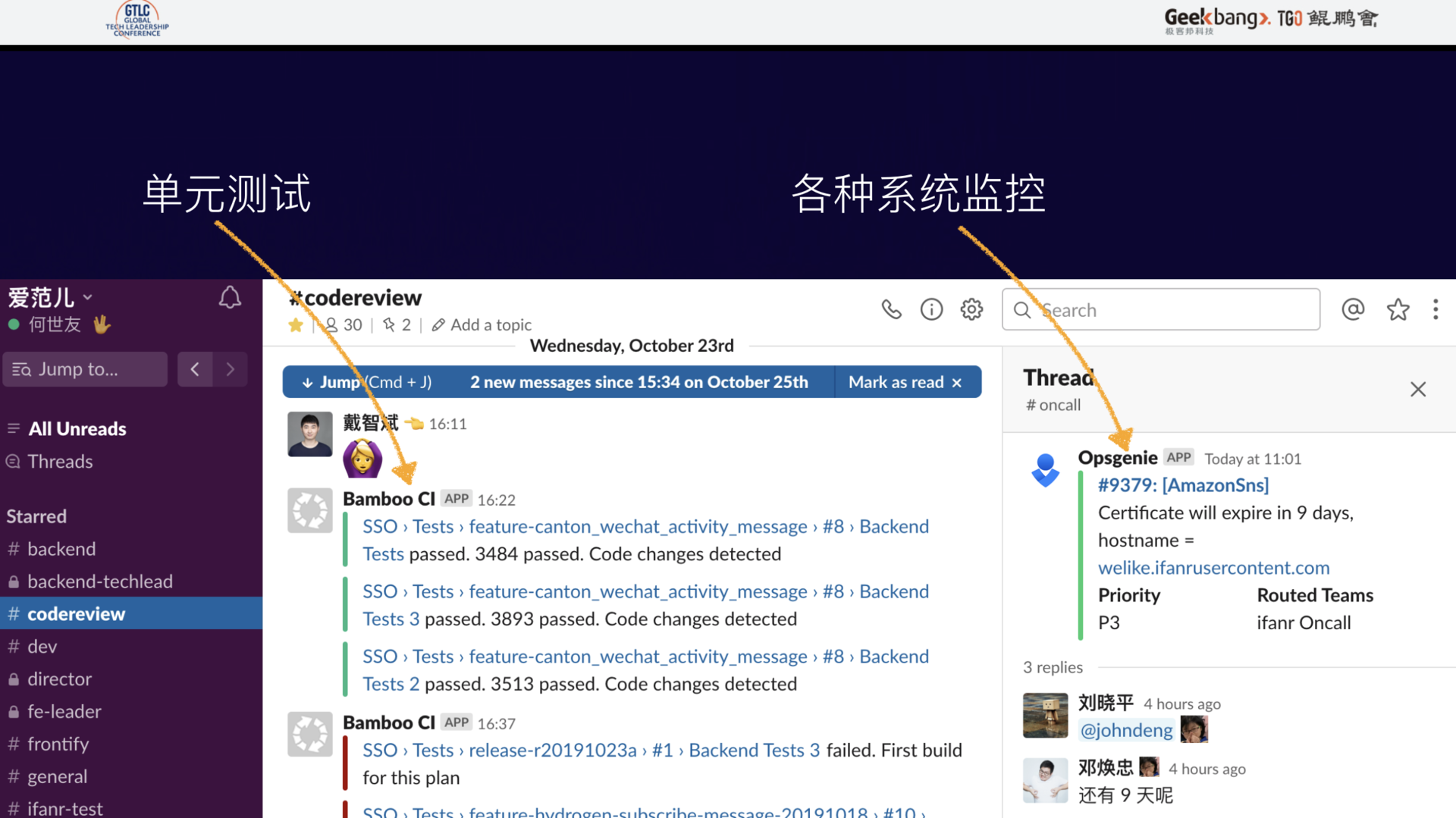
在这里,我可以提供一种参考,在 Slack 上,可以将 CI 系统的测试通知、OnCall 系统的报警消息集成进来,比如在代码审查群组中,除了需要参加审查的工程师和若干个关键的系统之外,都会在这里发生直接的交流,让一个上下文 Context 容纳更多的信息。
Slack 还支持配置一些 Actions,让我们可以直接在 Slack 消息对机器的消息进行交互,比如确认一个 issue 等。
如果能顺利完成一切,那么整个流程就可以愉快的运作起来。最后,就只剩下如何对工作结果进行评估的问题了。
不得不说,时至今日,仍然有很多团队在实行日报、周报等汇报方式。有时候,我都不得不深思:这究竟是人性的扭曲,还是道德的(败坏)……
大家想一想,上述提到的那么多系统和工具,都已经将工程师每天做什么任务、花了多长时间,这个团队本月完成了多少需求、上线了多少个版本都记录得非常翔实,那么为何还要采用人工汇报的方式?
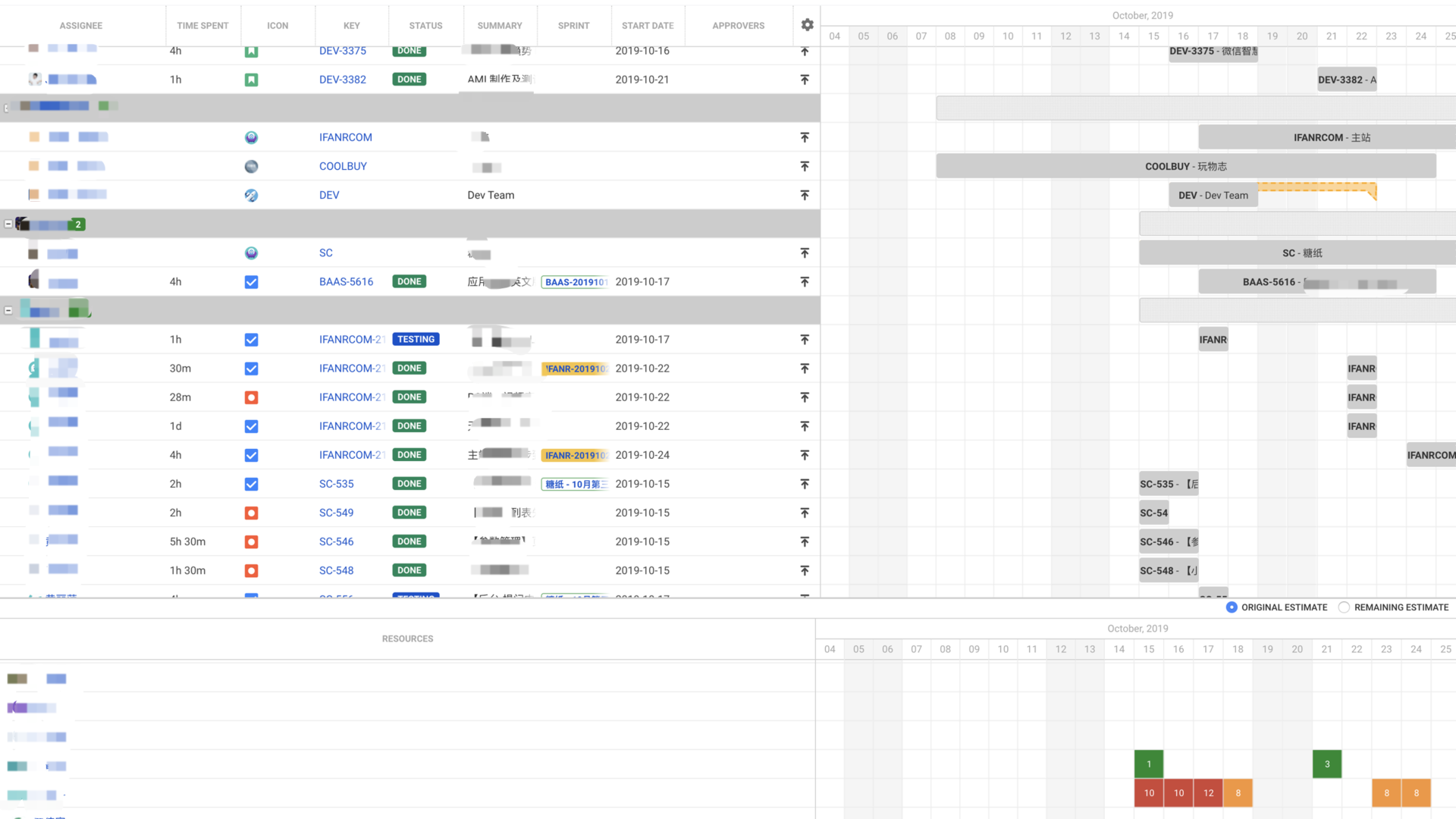
一般我会推荐通过数据化的工作进行结果评审,或许能更好的判定绩效,同时能提供给员工更多一对一面谈的对等交流机会,实现有效关照员工和组织成长。
这里可能有同学会疑惑,这些花费的时间是怎么统计的呢?难不成是工程师还得去一条条填写?不存在的。上述中所提到的系统间的连通,就是为了解决这些低效的人工处理数据同步的问题。我们通过每一次代码提交的描述信息,即可完成任务关联、工作时间的上报,甚至是开启下一个流程。
最后总结下,核心思想就三点:
1、关注项目和组织的长期生长,关注各个消耗环节,通过流程和系统斧正效率;
2、最大程度发挥岗位的核心价值,工程师的核心价值是在给定的资源和问题下,交付最合理的解决方案,其他都是额外的负担,这些额外的负担尽可能用机器和流程去节省掉;
3、最大程度实践公司的核心价值,不要轻易投入资源到这些内部系统的研发中,该花钱采购就采购,随着规模变大,内部系统的代价会超出想象。帮公司赚更多的钱,买更好的系统才是王道。
此次分享受限于时间,未尽之处还请谅解,期待后续更多的交流。去年,我在《极客时间技术领导力》专栏中写了两篇文章,更加聚焦在实践层面,欢迎各位感兴趣的朋友阅读指正。